Last week, Nandan Nilekani, former chairman of the Unique Identification Authority of India (UIDAI), and his associates mostly comprising of technologists, presented their vision of how India should deal with the upcoming and unstoppable data deluge.
In short, their argument went like this.
1. Indians will become data rich, before they become economically rich.
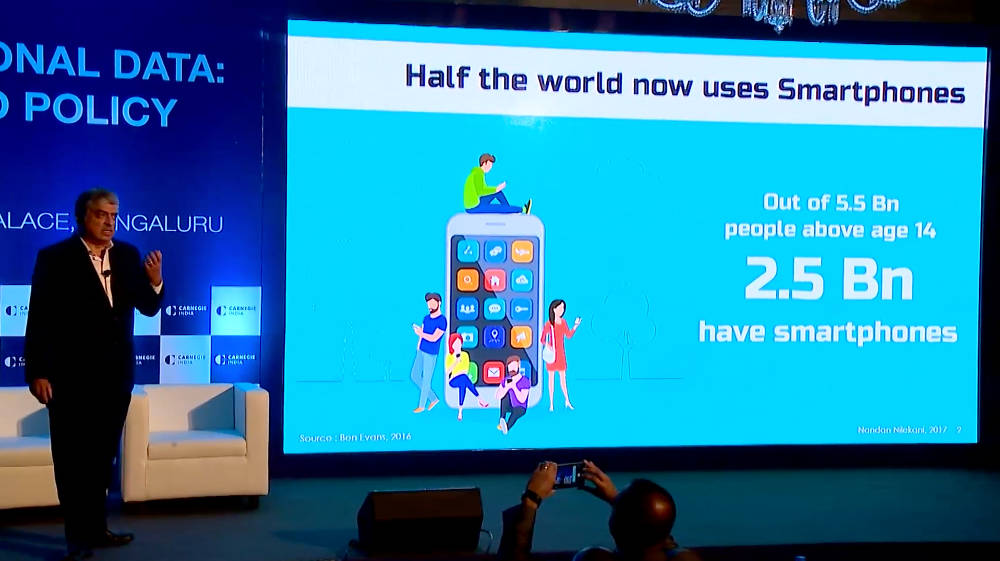
This is thanks mainly to the increasing digitisation of the economy. It's being driven by smartphones; by digital infrastructure such as Aadhaar, eKYC, eSign, Aadhaar Pay, unified payments interface (UPI), DigiLocker; and by a growing number of services and apps that are being built on these platforms. The trend will accelerate in the coming days with falling prices of sensors, and adoption of Internet of Things. Indians across the income pyramid will be generating an unprecedented volume of data.

[A slide from Nandan Nilekani’s presentation at the Carnegie India event, ‘Who Owns Personal Data: Technology and Policy Frameworks’]
2. Current thinking on data favours businesses rather than individuals.
Companies such as Google, Facebook, Amazon, and Netflix in the US, and Alibaba, Tencent and Baidu in China have been capturing market share, disrupting entire industries based on the data they collect from users. With investments in machine learning and artificial intelligence, their ability to crunch data will go up exponentially—making them winners in a winner takes all market. Users, on the other hand, have little control over their own data and are not in a position to use it for their own benefit. (That is, I as an individual will have more control over my own data, and can use it for my own benefit, getting better loans, better insurance, better healthcare and so on).
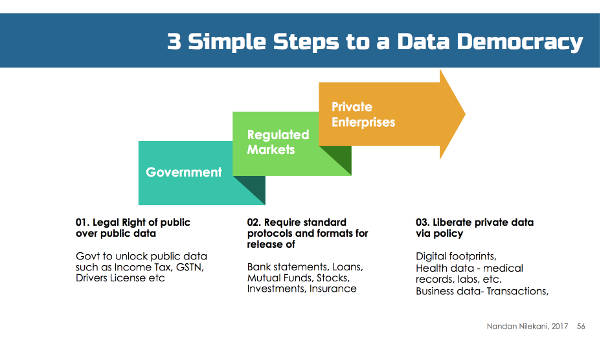
3. India is in a unique position to give ownership and control of data to users through law and technology.
Legal/policy: Let the government open its own data such as income tax to users; let regulators demand that companies provide data to users in standard, machine-readable format, and finally, pass laws to ensure data with private players—such as health data, financial transactions, etc—can be managed by individual users through a consent framework.
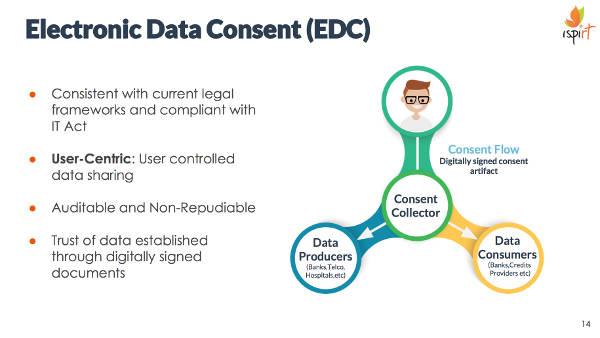
Technology: Nilekani’s team introduced ‘Data empowerment and protection architecture’—a system that allows the data to flow from one entity (data collectors such as banks or diagnostic centres) to another entity (data consumers such as lenders who can decide on the credit-worthiness of an individual by looking at bank statements, or a hospital which can look look at diagnostic data from different centres to provide treatment) based on the user’s consent.
[A slide from Sanjay Jain's presentation at the Carnegie India event, ‘Who Owns Personal Data: Technology and Policy Frameworks’]
While consent is usually understood as giving consent to ‘a data collector’ to use and share our data, in this framework, it is meant as a command to a ‘data collector’ to share our data with a specific entity for our benefit.
It’s a paradigm shift. From data being seen as something that is used to sell things to the users, it will be seen as something that will empower and benefit the user. Nilekani called it inversion of data.
Watch Nilekani’s presentation here:
After the session I spoke with a number of attendees. Almost everyone agreed it was a great idea, but said it will face huge resistance. Sanjay Anandram, a venture capitalist, said some resistance will come because of ignorance. But a lot of it will come from businesses that wouldn’t want to let go of data. “Why would they?” he asked. Some were concerned about the technology framework, while acknowledging that it’s still early stages, and that it would get better with more feedback and iterations. The technologists who worked on it seemed keen to get critical feedback so they can make it better. But, few believed the road ahead will be smooth.
Lessons from UPI
One way to get a sense of the challenges the consent framework will face is to look at what happened to UPI, launched by the National Payments Corporation of India late last year. The consent architecture is a bit like UPI. UPI helps you transfer funds from one account (the money in your bank account) to another (the receiver’s bank account) with your consent/on your instruction for your benefit—for example, to pay your shopping bills. Similarly, the consent architecture helps you to share data from one entity to another with your consent/instruction for some benefit—for example, your fitness data so you can get a better insurance cover.
However, the kind of data we are talking about is much more complex than money—by an order of magnitude. In his presentation, Sanjay Jain, chief innovation officer at the Centre for Innovation, IIM-A and a volunteer at iSpirt, said the architecture covers three types of data
- Personal data, such as KYC data, marksheets etc
- Generated data, such as raw location history, bank transaction history
- Derived data (intelligence) such as personalised keyboard dictionary, credit score, etc.
Most people understand money, and know what they are getting into when they agree to transfer it. That’s not the case with many other types data, even among those who understand it. It covers a whole gamut, and the complexity differs from sector to sector.
Manish Sharma, founder, HCITExpert Forum, said, “Healthcare records are more complex than UPI or loan transactions. You need a lot of consensus and discussions to get the data out.”
Those who downloaded UPI apps, especially when they were just launched, had to face several glitches. There is no reason to believe electronic data consent apps will be any better or even as good. The higher the complexity, the more difficult it is to build technology solutions around it.
The biggest challenge, however, will come from businesses themselves. In the case of UPI, early this year, there was a big standoff between ICICI Bank and Phonepe, a payments app based on UPI, after the bank blocked all transactions done on UPI. It’s similar to the resistance mobile number portability faced from telecom players. Businesses see user data as a moat, as a barrier to exit (for users) and entry (for competitors). They will resist any attempt to make them share ownership of that data with the users—which would mean letting them move on to a competitor.
Expect them to join hands and use every argument in the book from security, privacy and the dangers of government intervention to oppose any move towards that. Like Adam Smith said, “People of the same trade seldom meet together, even for merriment and diversion, but the conversation ends in a conspiracy against the public, or in some contrivance to raise prices.”
However, we might be getting ahead of ourselves when we talk about the big challenges. The consent framework is likely to be rolled out and be adopted step by step, perhaps starting with school students being able to give consent to universities to access their mark sheets directly from CBSE using DigiLocker. And then, by fintech startups and gradually by the bigger players. Meanwhile, the technology will get better too. We see that happening in UPI. The second version of UPI, the so-called UPI 2.0, is expected to hit the market in the next couple of months with better and more features.
Chinese philosopher Lao Tsu said, “A journey of thousand miles begins with a single step.” This might be the time to take that first step.
[Panel discussion on the policy aspects of the consent architecture]



Srikanth ??????????? on Aug 23, 2017 2:05 p.m. said
The lesson from UPI would be, no #databack for people. After 1 year of UPI live, *NO DATA* on transaction failures. #Data #Empowerment The biggest challange would be to gain trust when data economy is thrusted upon with out government forming regulators (Payments regulator was promised, but its still some cozy room in RBI inaccessible to public). Forget Companies sharing data with regulator when regulator doesnt exist and people getting back data through regulators and seeing transparent / accountable institutions (be it private / government) in being fair, demostrating abusive behaviour is absent. That trust can be gained by opening data and that has to integral part of the data democracy. Sadly, UIDAI, NPCI themselves do not reveal data when its not convinient. This doesnt help gain trust.
Tanuj Bhojwani on Aug 23, 2017 10:41 a.m. said
Good piece. But I think one major part of this talk and why Nandan is so public with it, is to accelerate the timeline of government action on this front. All the threats you mention are correct. But the biggest threat is inaction. Either by legislature or executive to curb the growing threat by data companies in a winner take all scenario where the paradigm that data is owned by platform and used to sell. Eric Schmidt once said "Big Data is so powerful nation states will fight over it". But somehow India hasn't even gotten the memo and we haven't made even basic data protection laws yet. The inversion is a chance to not get bullied into the usual insufficient regulatory regime by the same kind of lobbying and advocacy as is happening in the west. India needs to set a paradigm where we say, the user and her development is central, all policies and laws stem from that principle, not from protection.
Tanuj Bhojwani on Aug 23, 2017 10:41 a.m. said
Good piece. But I think one major part of this talk and why Nandan is so public with it, is to accelerate the timeline of government action on this front. All the threats you mention are correct. But the biggest threat is inaction. Either by legislature or executive to curb the growing threat by data companies in a winner take all scenario where the paradigm that data is owned by platform and used to sell. Eric Schmidt once said "Big Data is so powerful nation states will fight over it". But somehow India hasn't even gotten the memo and we haven't made even basic data protection laws yet. The inversion is a chance to not get bullied into the usual insufficient regulatory regime by the same kind of lobbying and advocacy as is happening in the west. India needs to set a paradigm where we say, the user and her development is central, all policies and laws stem from that principle, not from protection.